关关采集器主要注意的是两个文件夹
rules文件夹、log文件夹:
Rules是我们放关关采集规则的地方;
log是记日志的东西,就是关关采集器出错的时候会记录错误的信息,我们看到这个就知道采集出错在哪里了;
现在我们点开关关采集器,直接打开NovelSpider.exe,就可以启动关关采集器了。(注:打开的过程会有点慢,所以点击一次就等一下。千万不要再点打开,否则在一段时间后会打开多个关关采集器!)
有些关关会出现提示框,我们不管它直接关掉。
了解关关采集器的一些常用的东西
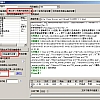
打开之后,我们应该立刻修改“设置(S)”→系统设置。:
1.修改本地网站目录,比如,我的在D:\xiaoshuo
2.再修改数据库连接字符串
DataSource=127.0.0.1;
Database=数据库名称;
UserID=数据库管理用户名;
Password=数据库管理密码;
port=3306;
charset=gbk
本帖隐藏的内容
这上面是设置关关采集器的东西,就是第一次用的时候要设置,设置好了就不需要再设置了。
关于“关关采集器1.7”分类设置
第一:分类设置一般用大类对应,这些对应你网站的类别。譬如
1|玄幻奇幻=,玄幻,奇幻,魔法,魔幻,玄幻魔法,奇幻玄幻,玄幻小说,玄幻·魔幻,玄幻异界,玄幻奇幻,
1是你网站第一个蓝米玄幻奇幻,等号后面的是采集目标网站可能遇到的分类,越详细越好,一些模板网站对应你的玄幻奇幻没有的,你就添加进去。
第二:是设置里面的生成
默认不需要修改,第一个生成目录页html是你网站小说目录页的html,如果你网站用的是伪静态那就不需要生成,第二个生成内容页html这个是小说内容的点击去看小说的文字章节,这个和上面第一个一样,如果你网站用的是伪静态那就不需要生成。
如果在建静态小说网站的话就需要生成了,这个很耗费硬盘的。一般1000本小说都要几G的空间了。
第三:生成全文阅读。不用管他一般用不到。
第四:生成OPF。这个是一定要生成的要不网站打不开,你的小说网站也是如果不生成是打开错误的。这里打勾就行了。其他的设置不要管,没有特殊要求是用不到的。
(注意:【设置–的电子书设置】这个不需要管,默认即可,所以的勾勾都不要选,设置里面的图片设置也是默认即可,所以的勾勾都不要选。)
第五:文字广告。如果你想在你的小说内容里面添加广告可以在这打上内容,看需要选择第一个入库章节添加文字广告真实入库也就是会把你的广告添加入你采集下来的小说,files/article/txt/0/1这些路径的txt文档里面
这个,你的小说是手机版所以需要选择第一个,在你添加广告的时候,章节阅读会看到不过还是不要用这些功能。
第六:其他【过滤替换】、【文字转图片】。不需要管
第七:日志选择。全部打勾就可以,这个是采集遇到的记录错误的日志,可以根据这个排除错误。
如何看关关规则行不行
点击规则,进入规则管理器,我们选择做不的那个三角型符号下拉选择你要测试的规则点击右边的载入,然后点击”测试规则”,就会弹出一个界面,如果出现这些这个是获取ID和小说名字
这个是获得小说信息内容包含小说名字分类简介和封面。
有些网站这些信息没有采集全,我们采集回来的话也会出现不全的这个没什么影响,主要小说章节内容可以看就行了。然后这些是获取采集的章节,这个是获取小说的内容。
这样就是一个好的采集规则我们可以用这个采集规则去采集小说更新了。
如何采集
一般,我们使用的是标准采集模式。
我们点“采集–标准采集模式”有时候会出现错误提示,不管我们在采集框架随便点一个规则,他就会出现正的位置了还有一些出现什么提示我们也是忽略他直接点击【继续】就可以了。
进入标准采集后正确的姿势后,一般用的是第一个按目标站页面获取编号,这个我们规则写的时候都是按目标站最近更新的小说设置的,采集的时候会自动采集对方更新的小说我们更新的时候也会跟着别人的小说网站更新。
1.设置好ID的范围,按目标站ID采集很少用到一般需要特殊采集对方的某一本书采集的时候才采集。
2.按目标站ID采集很少用到一般需要特殊采集对方的某一本书采集的时候才采集。
3.按自己网站的小说ID采集的,也是要更新自己网站的某一本小说才点击,但是模板站不一定有这本书,所以采集起来很慢。很少用、基本没用。
4.到最下面的日志记录这个一定个要选上会记录采集小说的到时候无缘无故出现采集不了的信息。循环采集这个也一定要选上,这个是自动采集的时候保证采集器自动循环采集对方的网站,循环时间设置看你自己的需求,我一般设置是十分钟。如果你想不停采集那设置为零。